
I’ve mentioned to several colleages in the past about my concern about AI accuracy. During my time at school. UK education went through a transition of allowing calculators in the classrooms, and shortly after into exams. One lesson that was drummed into us from an early age when using a calculator was in anticipating the result you were expecting,
1,126 / 2 for example. You know it will be less than 1,126 and more than 2, you would expect the answer to begin with a 5… you get the idea..
Purely relying upon the results given without knowing an approximation of what you are expecting and entering that into your test paper was a sure way of getting a fail. And the same can be said for what people are doing with AI chatbots today.
Yes, you can be more specific to get more accuracy. Yes, you can be very good at promp crafting to improve return accuracy. But ultimatly, there is a risk of innacuracy inherent with AI, especially when using public domain data when you dont verify the result or the accuracy of the answer.
Given this premis and the fact that most AI use open source “public” data to generate (AI doesn’t create anything, it just filters large data sets to find your answers, please read more on this here) to provide their returned answers. Its only logical to assume that over time, as more AI generated content make their way into public domain data sets, that this will exaserbate the innacuracy we see today that could eventually render AI returned results as useless.
Current Accuracy Today
The accuracy of AI-generated content today is not a single, fixed number. It varies dramatically based on the model, the complexity of the query, and the domain.
- Hallucination Rates: Research and benchmarks show that even the most advanced models have a non-trivial rate of hallucination, where they confidently produce factually incorrect or nonsensical information. Recent studies place the hallucination rate for top-tier models like GPT-4 as low as 15% in some benchmarks, but other tests on more complex, domain-specific questions (like oncology) show hallucination rates of over 20%. More advanced reasoning models have even shown higher hallucination rates in certain tests.
- Domain Specificity: The accuracy is highest for general knowledge questions where the data is abundant and consistent. It drops significantly for specialized, niche, or recently developed topics.
- Truth vs. Plausibility: AI models are trained to predict the most statistically probable next word, not to be truthful. This often results in a fluent, convincing answer that is factually wrong, which makes hallucinations particularly difficult for a user to detect.
Overall, a reasonable estimate for the current accuracy of a leading AI model on a general range of questions is likely 70-85%, but this figure is highly conditional and can be much lower in specific contexts.
Source: https://huggingface.co/spaces/vectara/Hallucination-evaluation-leaderboard
Source: https://openai.com/index/gpt-4-research/

The “Model Collapse” Problem
My premise (as mentioned above) is directly addressed by a phenomenon that AI researchers call “model collapse.” This concept describes what happens when a new generation of AI models is trained on data that is increasingly contaminated by the outputs of older, less accurate AI models.
- Eroding the “Truth”: As AI-generated content (synthetic data) proliferates on the internet, it gets scraped and included in the training datasets for future AI models. This can lead to a positive feedback loop of inaccuracies.
- Loss of Diversity: Research shows that repeatedly training models on synthetic data causes them to lose information about the “long tail” of data—the rare, unique, or less-common facts and ideas. The models start to converge on a “mean,” producing answers that are less varied and more generic, eventually leading to a complete loss of meaningful output.
- Analogous to Photocopying: A simple analogy is photocopying a document repeatedly. Each new copy is slightly degraded, losing a bit more detail from the original. Eventually, after many generations, the copy is a blurry, unrecognizable mess.
Source: https://www.ibm.com/think/topics/model-collapse
Extrapolating to the Future
Given the complex dynamics of AI development, here’s a plausible (but not guaranteed) forecast for the trajectory of AI accuracy.
- 1 Year: Slight decrease in accuracy. Within the next year, the effects of data contamination will likely begin to be noticeable. While developers will be working on solutions, the sheer volume of AI-generated data entering the public domain will make it harder to curate clean, human-generated datasets. Accuracy could see a small but measurable decline, perhaps from the 70-85% range to 70-80%.
- 2 Years: Accelerated decline, then potential stabilization. The model collapse problem will become more acute. New, less-resourced AI developers who rely on publicly scraped data will be hit hardest, creating a significant quality gap. However, major AI companies with the resources to create and maintain proprietary, human-curated datasets will have a competitive advantage. This could lead to a bifurcation in the market, with some models becoming less accurate while others are protected. The average accuracy across all publicly available models may drop to 60-75%.
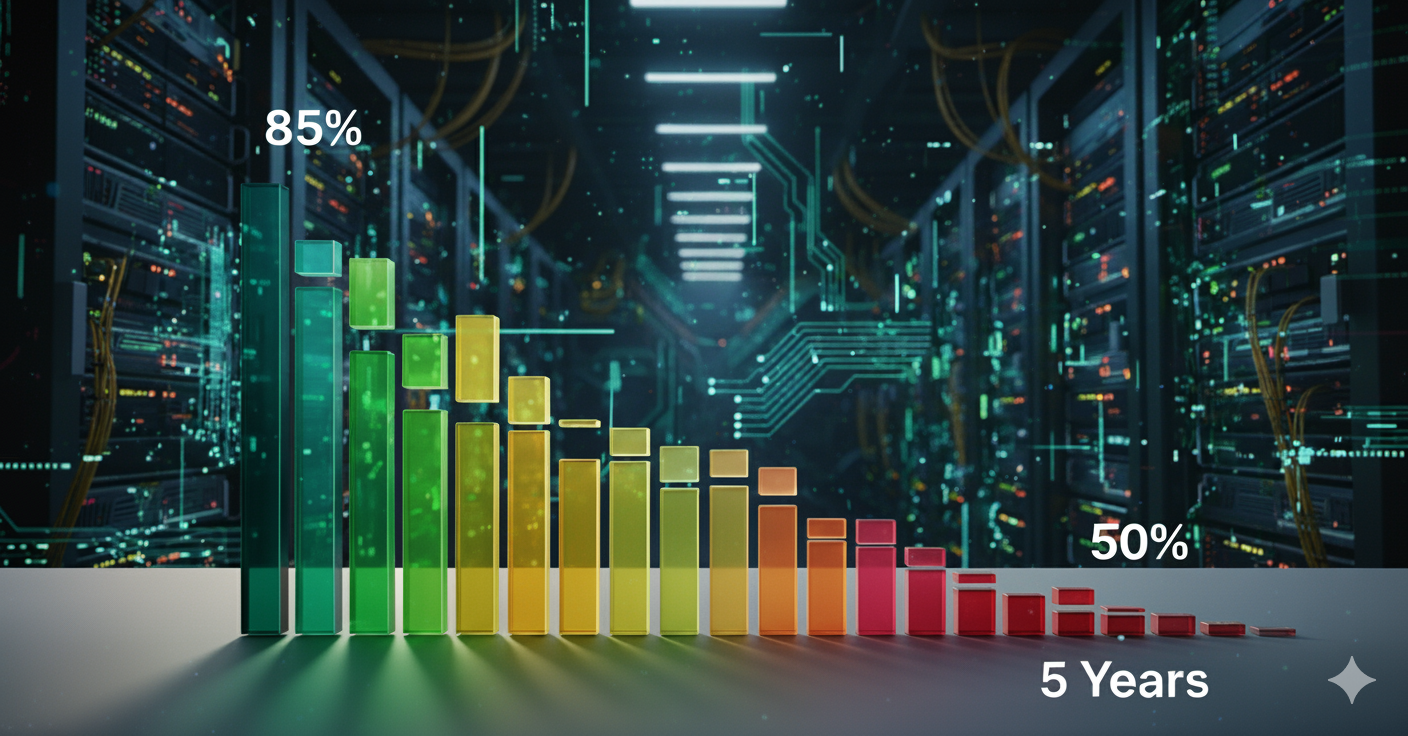
- 5 Years: Significant divergence. The market will likely be clearly divided. High-end, premium models from major companies, which have invested heavily in creating and protecting their proprietary “clean” data, will have likely stabilized or even slightly improved their accuracy. These models could reach an accuracy of 80-90% for general questions. Conversely, models relying on public data will have degraded significantly due to model collapse, with some becoming virtually useless for factual inquiries. Their accuracy could fall to below 50%.
- 10 Years: A new paradigm. The concept of “free AI” trained on public data may have become obsolete for fact-based queries. The most accurate AI models will be those trained on exclusive, verified, and continuously updated datasets. The value of human-generated, “uncontaminated” data will be at an all-time high, becoming a prized asset. The public AI landscape will likely be very different from today’s, with accuracy being a premium feature rather than a baseline expectation.
Its worth pointing out that this “potential” is only an extrapolation and not a certanty when looking at AI tools (chat bots etc) that use public data (wiki, reddit etc) as their sole source of data to return results, and not the “closed” data models used within organisations that can verify the accuracy of the data used and also verify the accuracy of the answers before using them.
So as I started this blog off by say…. Be carefull what you ask for.



